데이터 집계와 그룹 연산(2)
데이터 집계와 그룹 연산(2)
변위치 분석과 버킷 분석
pandas의 cut과 qcut 메서드를 사용해서 선택한 크기만큼 혹은 표본 변위치에 따라 데이터를 나눌 수 있었다. 이 함수들을 groupby와 조합하면 데이터 묶음에 변위치 분석이나 버킷 분석을 매우 쉽게 수행할 수 있다. 임의의 데이터 묶음을 cut을 이용해서 등간격 구간으로 나누어보자
frame = pd.DataFrame({'data1':np.random.randn(1000),
'data2':np.random.randn(1000)})
frame.head()
quartiles = pd.cut(frame.data1, 4)
quartiles[:10]
0 (-1.714, -0.0799]
1 (-0.0799, 1.554]
2 (-1.714, -0.0799]
3 (-0.0799, 1.554]
4 (-0.0799, 1.554]
5 (-0.0799, 1.554]
6 (-1.714, -0.0799]
7 (-1.714, -0.0799]
8 (-1.714, -0.0799]
9 (-0.0799, 1.554]
Name: data1, dtype: category
Categories (4, interval[float64, right]): [(-3.354, -1.714] < (-1.714, -0.0799] < (-0.0799, 1.554] < (1.554, 3.188]]
cut에서 반환된 Categorical 객체는 바로 groupby로 넘길 수 있다.
def get_stats(group):
return {'min':group.min(), 'max':group.max(),'count':group.count(), 'mean':group.mean()}
grouped = frame.data2.groupby(quartiles)
grouped.apply(get_stats).unstack()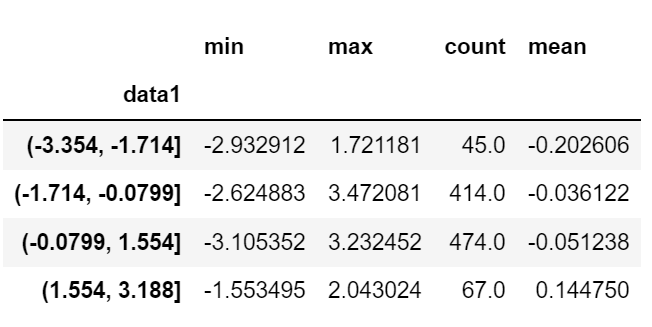
등간격 버킷이었고, 표본 변위치에 기반하여 크기가 같은 버킷을 계산하려면 qcut을 사용한다. 나는 labels=False를 넘겨서 변위치 숫자를 구했다.
변위치 숫자를 반환
grouping = pd.qcut(frame.data1, 10, labels=False)
grouping[:10]
0 2
1 9
2 3
3 8
4 8
5 7
6 1
7 3
8 2
9 7grouped = frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()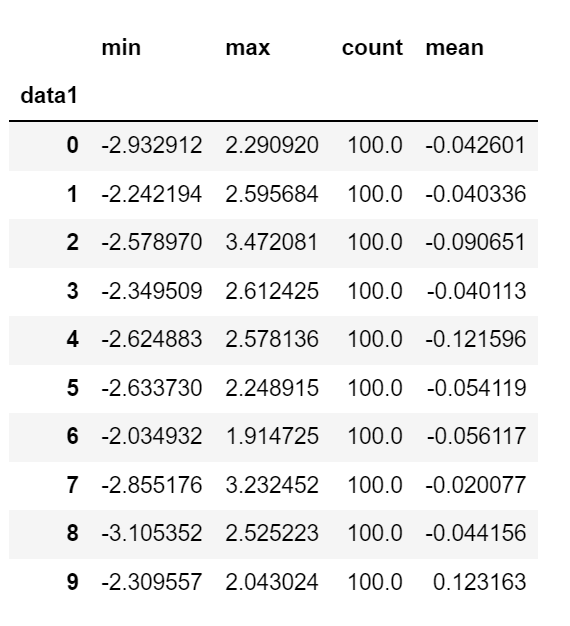
그룹에 따른 값으로 결측치 채우기
누락된 데이터를 정리할 때면 어떤 경우에는 dropa를 사용해서 데이터를 살펴보고 걸러내기도 한다. 하지만 어떤 경우에는 누락된 값을 고정된 값이나 혹은 데이터로부터 도출된 어떤 값으로 채우고 싶을 때도 있다. 이런 경우 fillna 메서드를 사용하는데, 누락된 값을 평균값으로 대체하는 예제를 살펴보자
s = pd.Series(np.random.randn(6))
s0 0.487854
1 0.655381
2 0.043892
3 0.712731
4 -0.110462
5 0.267141
dtype: float64
s[::2] = np.nan
ss.fillna(s.mean())
0 0.545084
1 0.655381
2 0.545084
3 0.712731
4 0.545084
5 0.267141
dtype: float64그룹별로 채워 넣고 싶은 값이 다르다고 가정해보자. 아마도 추측했듯이 데이터를 그룹으로 나누고 apply 함수를 사용해서 각 그룹에 대해 fillna를 적용하면 된다. 여기서 사용된 데이터는 동부와 서부로 나눈 미국의 지역에 대한 데이터다.
states =['Ohio','New York','Vermont','Florida','Oregon','Nevada','California','Idaho']
group_key = ['East'] * 4 + ['west'] * 4
group_key
['East', 'East', 'East', 'East', 'west', 'west', 'west', 'west']['East'] *4는 ['East'] 리스트 안에 있는 네 벌의 원소를 이어붙인다. 리스트를 더하면 각 리스트를 이어붙일 수 있다.
data = pd.Series(np.random.randn(8), index= states)
data
Ohio 0.645470
New York 0.847592
Vermont -0.744233
Florida -1.932034
Oregon -0.864817
Nevada 1.681973
California -0.110637
Idaho 0.176455
dtype: float64데이터에서 몇몇 값을 결측치로 만들어보자
data[['Vermont','Nevada','Idaho']] = np.nan
data
Ohio 0.645470
New York 0.847592
Vermont NaN
Florida -1.932034
Oregon -0.864817
Nevada NaN
California -0.110637
Idaho NaN
dtype: float64data.groupby(group_key).mean()
East -0.146324
west -0.487727
dtype: float64다음과 같이 누락된 값을 그룹의 평균값으로 채울 수 있다
fill_mean = lambda g:g.fillna(g.mean())
fill_mean
<function __main__.<lambda>(g)>data.groupby(group_key).apply(fill_mean)
Ohio 0.645470
New York 0.847592
Vermont -0.146324
Florida -1.932034
Oregon -0.864817
Nevada -0.487727
California -0.110637
Idaho -0.487727
dtype: float64그룹에 따라서 미리 정의된 다른 값을 채워 넣어야 할 경우도 있다. 각 그룹은 내부적으로 name이라는 속성을 가지고 있으므로 이를 이용하자
fill_values ={'East' :0.5, 'West':-1}
fill_func = lambda g:g.fillna(fill_values[g.name])
data.groupby(group_key).apply(fill_func)
Ohio 0.645470
New York 0.847592
Vermont 0.500000
Florida -1.932034
Oregon -0.864817
Nevada -1.000000
California -0.110637
Idaho -1.000000
dtype: float64랜덤 표본과 순열
대용량의 데이터를 몬테카를로 시뮬레이션이나 다른 애플리케이션에서 사용하기 위해 랜덤 포본을 뽑아낸다고 해보자. 뽑아내는 방법은 여럭 가지가 있는데, 여기서는 Series의 sample 메서드를 사용하자.
예시를 위해 트럼프 카드 덱을 한번 만들어보자
# 하트, 스페이드, 크럽, 다이아몬드
suits =['H','S','C','D']
card_val = (list(range(1, 11)) + [10] * 3) *4
base_names =['A'] + list(range(2,11)) + ['J','k','Q']
cards=[]
for suit in ['H','S','C','D']:
cards.extend(str(num) + suit for num in base_names)
deck = pd.Series(card_val, index=cards)
deck[:13]
AH 1
2H 2
3H 3
4H 4
5H 5
6H 6
7H 7
8H 8
9H 9
10H 10
JH 10
kH 10
QH 10
dtype: int64블랙잭 같은 게임에서 사용하는 카드 이름과 값을 색인으로 하는 52장의 카드가 Series 객체로 준비되었다.(단순히 하기 위해 에이스 'A'를 1로 취급했다.
5장의 카드를 뽑기 위해 다음 코드를 작성한다.
def draw(deck, n=5):
return deck.sample(n)
draw(deck)JH 10
4D 4
10D 10
5S 5
4H 4
dtype: int64각 세트(하트, 스페이드, 클럽, 다이아몬드)별로 2장의 카드를 무작위로 뽑고 싶다고 가정하자. 세트는 각 카드 이름의 마지막 글자이므로 이를 이용해서 그룹을 나누고 apply를 사용하자.
get_suit = lambda card: card[-1]
deck.groupby(get_suit).apply(draw, n=2)
C 6C 6
2C 2
D 7D 7
8D 8
H 3H 3
JH 10
S AS 1
8S 8
dtype: int64아래와 같은 방법으로 각 세트별 2장의 카듣를 무작위로 뽑을 수도 있다 .
deck.groupby(get_suit, group_keys=False).apply(draw, n=2)
AC 1
5C 5
4D 4
2D 2
kH 10
2H 2
6S 6
JS 10
dtype: int64
그룹 가중 평균과 상관관계
groupby의 나누고 적용하고 합치는 패러다임에서 (그룹 가중 평균과 같은) DataFrame의 컬럼 간 연산이나 두 Series 간의 연산은 일상적인 일이다. 예를 들어 그룹 키와 값 그리고 어떤 가중치를 갖는 다음 데이터 묶음을 살펴보자.
df = pd.DataFrame({'category':['a','a','a','a','b','b','b','b'],
'data':np.random.randn(8),
'weights':np.random.rand(8)})
df
grouped = df.groupby('category')
get_wavg = lambda g:np.average(g['data'], weights=g['weights'])
grouped.apply(get_wavg)category
a 0.047714
b 0.158672
dtype: float64
야후! 파이낸스에서 가져온 몇몇 주식과 S&P 500 지수(종목 코드 SPX)의 종가 데이터를 살펴보자.
close_px = pd.read_csv('examples/stock_px_2.csv', parse_dates=True, index_col=0)
close_px.head(3)
close_px.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 2214 entries, 2003-01-02 to 2011-10-14
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 AAPL 2214 non-null float64
1 MSFT 2214 non-null float64
2 XOM 2214 non-null float64
3 SPX 2214 non-null float64
dtypes: float64(4)
memory usage: 86.5 KBclose_px[-4:]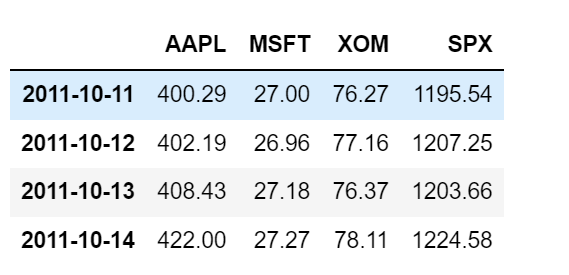
퍼센트 변화율로 일일 수익률을 계산하여 연간 SPX 지수와의 상관관계를 살펴보는 일은 흥미로 울 수 있는데, 다음과 같이 구할 수 있다. 우선 'SPX' 컬럼과 다른 컬람의 상관관계를 계산하는 함수를 만든다.
spx_corr = lambda x: x.corrwith(x['SPX'])pct_change 함수를 이용해서 close_px의 퍼센트 변화율을 계산한다.
rets = close_px.pct_change().dropna()
rets[:3]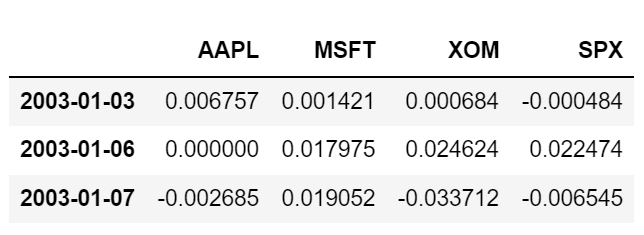
각 datetime에서 연도 속성만 반환하는 한줄 짜리 함수를 이용해서 연도별 퍼센트 변화율을 구한다.
get_year = lambda x:x.year
by_year = rets.groupby(get_year)
by_year.apply(spx_corr)

두 컬럼 간의 상관관계를 계산하는 것도 가능하다. 다음은 애플과 마이크로소프트 주가의 연간 상관관계다
by_year.apply(lambda g:g['AAPL'].corr(g['MSFT']))
2003 0.480868
2004 0.259024
2005 0.300093
2006 0.161735
2007 0.417738
2008 0.611901
2009 0.432738
2010 0.571946
2011 0.581987
dtype: float64그룹상의 선형회귀
pandas 객체나 스칼라값을 반환하기만 한다면 groupby를 좀 더 복잡한 그룹상의 통계 분석을 위해 사용할 수 있다. 예를 들어 계량경제 라이브러리 econometrics library인 statsmodels를 사용해서 regress라는 함수를 작성하고 각 데이터 묶음마다 최소제곱 Ordinary Least Squares, OLS 으로 회귀를 수행할 수 있다.
import statsmodels.api as sm
def regress(data, yvar, xvars):
Y = data[yvar]
X = data[xvars]
X['intercept'] = 1.
result = sm.OLS(Y,X).fit()
return result.params이제 SPX 수익률에 대한 애플(AAPL) 주식의 연간 선형회귀는 다음과 같이 수행할 수 있다.
by_year.apply(regress, 'AAPL', ['SPX'])
피벗데이블과 교차일람표
피벗테이블은 스프레드시트 프로그램과 그 외 데이터 분석 소프트웨어에서 흔히 볼 수 있는 데이터 요약화 도구다. 피벗테이블은 데이터를 하나 이상의 키로 수집해서 어떤 키는 로우에, 어떤 키는 컬럼에 나열해서 데이터를 정렬한다.
pandas에서 피벗테이블은 이 장에서 설명했던 groupby 기능을 사용해서 계층적 색인을 활용한 재형성 연산을 가능하게 해준다.
DataFrame에는 pivot_table 메서드가 있는데 이는 pandas 모듈의 최상위 함수로도 존재한다. (pandas.pivot_table).groupby를 위한 편리한 인터페이스를 제공하기 위해 pivot_table은 마진이라고 하는 부분합을 추가할 수 있는 기능을 제공한다.
팁 데이터로 돌아가서 요일(day)과 흡연자(smoker) 집단에서 평균(pivot_table의 기본 연산)을 구해보자.
tips.pivot_table(index=['day','smoker'])
이는 groupby를 사용해서 쉽게 구할 수 있는데, 이제 tip_pct와 size에 대해서만 집계를 하고 날짜(time)별로 그룹지어보자. 이를 위해 day로우와 smoker 칼럼을 추가했다.
tips.pivot_table(['tip_pct', 'size'], index=['time','day'],
columns = 'smoker')
이 데이블은 margins=True를 넘겨서 부분합을 포함하돋록 확장할 수 있는데, 그렇게 하면 All 컬럼과 All로우가 추가되어 단일 줄 안에서 그룹 통계를 얻을 수 있다.
tips.pivot_table(['tip_pct', 'size'], index=['time','day'],
columns='smoker', margins=True)
여기서 All 값은 흡연자와 비흡연자를 구분하지 않은 평균값(All 컬럼) 이거나 로우에서 두 단계를 묶은 그룹의 평균값(All 로우)이다.
다른 집계함수를 사용하려면 그냥 aggfunc로 넘기면 되는데, 예를 들어 'count'나 len함수는 그룹 크기의 교차일람표(총 개수나 빈도)를 반환한다.
tips.pivot_table('tip_pct', index=['time','smoker'], columns='day', aggfunc=len, margins=True)
만약 어떤 조합이 비어 있다면 (혹은 NA 값) fill_value를 넘길 수 있다.
tips.pivot_table('tip_pct', index=['time','size','smoker'],
columns='day', aggfunc='mean', fill_value=0)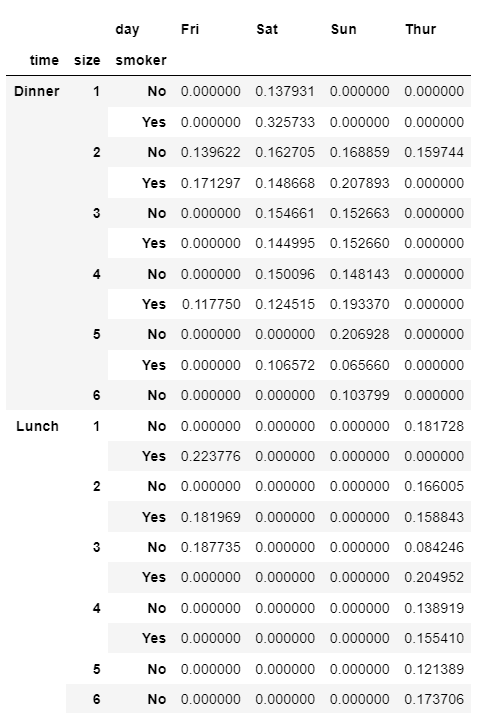
pivot_table 옵션
| 함수 | 설명 |
| values | 집계하려는 컬럼 이름 혹은 이름의 리스트, 기본적으로 모든 숫자 컬럼을 집계한다. |
| index | 만들어지는 피벗데이블의 로우를 그룹으로 묶을 컬럼 이름이나 그룹 키 |
| columns | 만들어지는 피벗데이블의 컬럼을 그룹으로 묶을 컬럼 이름이나 그룹 키 |
| aggfunc | 집계함수나 함수 리스트, 기본값으로 'mean'이 사용된다. groupby 컨텍스트 안에서 유효한 어떤 함수라도 가능하다. |
| fill_value | 결과 데이블에서 누락된 값을 대체하기 위한 값 |
| dropna | True인 경우 모든 항목이 NA인 컬럼은 포함하지 않는다. |
| margins | 부분합이나 총계를 담기 위한 로우/컬럼을 추가할지 여부. 기본값은 False |
교차일람표
교차일람표(또는 교차표)는 그룹 빈도를 계산하기 위한 피벗데이블의 특수한 경우다.
crosstab 함수의 처음 두 인자는 배열이나 Series 혹은 배열의 리스트가 될 수 있다. 팁 데이터에 대해 교차표를 구해보자.
pd.crosstab([tips.time, tips.day], tips.smoker, margins=True)