시계열time series (3)
시계열time series (3)
시간대 다루기
● 시간대 지역화와 변환
● 시간대를 고려해서 Timestamp 객체 다루기
● 다른 시간대 간의 연산
기간과 기간 연산
● Period의 빈도 변환
● 타임스탬프와 기간 서로 변환하기
● 배열로 PeriodIndex 생성하기
리샘플링과 빈도 변환
● 다운샘플링
● 업샘플링과 보간
● 기간 리샘플링
시간대 다루기
시계열을 다루는 많은 사용자는 현재 국제표준이며 그리니치 표준시를 계승하는 국제표준시 coordinated universal time, UTC 를 선택한다. 시간대는 UTC로부터 떨어지 오프셋으로 표현되는데 예를 들면 뉴욕은 일광절약시간 daylight saving time, DST 일때 UTC보다 4시간 늦으며 아닐 때는 5시간 늦다.
파이썬에서 시간대 정보는 전 세계의 시간대 정보를 모아둔 올슨 데이터베이스를 담고 있는 서드파티 라이브러리인 pytz에서 얻어온다. 이는 특히 역사적인 데이터를 다룰 때 중요한데 DST날짜 (그리고 심지어는 UTC 오프셋마저)는 지역 정부의 변덕에 따라 여러 차례 변경되었기 때문이다. 미국에서는 1900년부터 DST 시간이 수차례 변경되었다,
pandas는 pytz의 기능을 사용하고 있으므로 시간대 이름 외에 API의 다른 부분은 무시해도 상관없다.
import pytz
pytz.common_timezones[-5:]
['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
tz = pytz.timezone('America/New_York')
tz
<DstTzInfo 'America/New_York' LMT-1 day, 19:04:00 STD>pytz에서 시간대 객체를 얻으려면 pytz.timezone을 사용하면 된다.
시간대 지역화와 변환
기본적으로 pandas에서 시계열은 시간대를 엄격히 다루지 않는다.
rng = pd.date_range('3/9/2012 9:30', periods=6, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2012-03-09 09:30:00 -0.063371
2012-03-10 09:30:00 0.613313
2012-03-11 09:30:00 -0.187603
2012-03-12 09:30:00 -0.608165
2012-03-13 09:30:00 0.183288
2012-03-14 09:30:00 -0.453697
Freq: D, dtype: float64색인의 tz 필드는 None이다.
print(ts.index.tz)
None시간대를 지정해서 날짜 범위를 생성할 수 있다.
pd.date_range('3/9/2012 9:30', periods=10, freq='D', tz='UTC')
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00', '2012-03-16 09:30:00+00:00',
'2012-03-17 09:30:00+00:00', '2012-03-18 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
지역화 시간으로의 변환은 tz_localize 메서드로 처리할 수 있다.
ts_utc = ts.tz_localize('UTC')
ts_utc
2012-03-09 09:30:00+00:00 -0.063371
2012-03-10 09:30:00+00:00 0.613313
2012-03-11 09:30:00+00:00 -0.187603
2012-03-12 09:30:00+00:00 -0.608165
2012-03-13 09:30:00+00:00 0.183288
2012-03-14 09:30:00+00:00 -0.453697
Freq: D, dtype: float64ts_utc.index
DatetimeIndex(['2012-03-09 09:30:00+00:00', '2012-03-10 09:30:00+00:00',
'2012-03-11 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')시계열이 특정 시간대로 지역화되고 나면 tz_convert를 이용해서 다른 시간대로 변환 가능하다.
ts_utc.tz_convert('America/New_York')
2012-03-09 04:30:00-05:00 -0.063371
2012-03-10 04:30:00-05:00 0.613313
2012-03-11 05:30:00-04:00 -0.187603
2012-03-12 05:30:00-04:00 -0.608165
2012-03-13 05:30:00-04:00 0.183288
2012-03-14 05:30:00-04:00 -0.453697
Freq: D, dtype: float64위 시계열의 경우에는 America/New_York 시간대에서 일광절약시간을 사용하고 있는데, 동부표준시(EST)로 맞춘 다음 UTC 혹은 베를린 시간으로 변환할 수 있다.
ts_eastern = ts.tz_localize('America/New_York')
ts_eastern.tz_convert('UTC')
ts_eastern.tz_convert('Europe/Berlin')tz_localize와 tz_convert는 모두 DatetimeIndex의 인스턴스 메서드다.
ts.index.tz_localize('Asia/Shanghai')
DatetimeIndex(['2012-03-09 09:30:00+08:00', '2012-03-10 09:30:00+08:00',
'2012-03-11 09:30:00+08:00', '2012-03-12 09:30:00+08:00',
'2012-03-13 09:30:00+08:00', '2012-03-14 09:30:00+08:00'],
dtype='datetime64[ns, Asia/Shanghai]', freq=None)시간대를 고려해서 Timestamp 객체 다루기
시계열이나 날짜 범위와 비슷하게 개별 Timestamp 객체도 시간대를 고려한 형태로 변환이 가능하다.
stamp = pd.Timestamp('2011-03-12 04:00')
stamp_utc = stamp.tz_localize('utc')
stamp_utc.tz_convert('America/New_York')
Timestamp('2011-03-11 23:00:00-0500', tz='America/New_York')Timestamp 객체를 생성할 때 시간대를 직접 넘겨주는 것도 가능하다.
stamp_mosco = pd.Timestamp('2011-03-12 04:00', tz='Europe/Moscow')
stamp_mosco
Timestamp('2011-03-12 04:00:00+0300', tz='Europe/Moscow')시간대를 고려한 Timestamp 객체는 내부적으로 UTC 타임스탬프 값을 유닉스 에포크 Unix epoch(1970년 1월1일)부터 현재까지의 나초로 저장하고 있다. 이 UTC 값은 시간대 변환 과정에서 변하지 않고 유지된다.
stamp_utc.value
1299902400000000000
stamp_utc.tz_convert('America/New_York').value
1299902400000000000pandas의 DateOffset 객체를 이용해서 시간 연산을 수행할 때는 가능하다면 일광절약시간을 고려한다. DST로 전환되기 직전의 타임스탬프에 대한 예제를 살펴보자. 먼저 DST 시행 30분전의 Timestamp를 생성하자.
from pandas.tseries.offsets import Hour
stamp = pd.Timestamp('2012-03-12 01:30', tz='US/Eastern')
stamp
Timestamp('2012-03-12 01:30:00-0400', tz='US/Eastern')
stamp + Hour()
Timestamp('2012-03-12 02:30:00-0400', tz='US/Eastern')그리고 DST 시행 90분 전의 Timestamp를 생성하자
stamp = pd.Timestamp('2012-11-04 00:30', tz='US/Eastern')
stamp
Timestamp('2012-11-04 00:30:00-0400', tz='US/Eastern')
stamp + 2 * Hour()
Timestamp('2012-11-04 01:30:00-0500', tz='US/Eastern')다른 시간대 간의 연산
서로 다른 시간대를 갖는 두 시계열이 하나로 합쳐지면 결과는 UTC가 된다. 타임스탬프는 내부적으로 UTC 로 저장되므로 추가적인 변환이 불필요한 명료한 연산이다.
rng = pd.date_range('3/7/2012 9:30', periods=10, freq='B')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2012-03-07 09:30:00 -2.012329
2012-03-08 09:30:00 0.064263
2012-03-09 09:30:00 0.259144
2012-03-12 09:30:00 0.218048
2012-03-13 09:30:00 -0.097072
2012-03-14 09:30:00 1.088349
2012-03-15 09:30:00 -1.297369
2012-03-16 09:30:00 0.026768
2012-03-19 09:30:00 -0.413522
2012-03-20 09:30:00 1.917415
Freq: B, dtype: float64
ts1 = ts[:7].tz_localize('Europe/London')
ts2 = ts1[2:].tz_convert('Europe/Moscow')
ts1
2012-03-07 09:30:00+00:00 -2.012329
2012-03-08 09:30:00+00:00 0.064263
2012-03-09 09:30:00+00:00 0.259144
2012-03-12 09:30:00+00:00 0.218048
2012-03-13 09:30:00+00:00 -0.097072
2012-03-14 09:30:00+00:00 1.088349
2012-03-15 09:30:00+00:00 -1.297369
dtype: float64
ts2
2012-03-09 13:30:00+04:00 0.259144
2012-03-12 13:30:00+04:00 0.218048
2012-03-13 13:30:00+04:00 -0.097072
2012-03-14 13:30:00+04:00 1.088349
2012-03-15 13:30:00+04:00 -1.297369
dtype: float64
result = ts1+ts2
result.index
DatetimeIndex(['2012-03-07 09:30:00+00:00', '2012-03-08 09:30:00+00:00',
'2012-03-09 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq=None)기간과 기간 연산
며칠, 몇개월, 몇 분기, 몇 해 같은 기간은 Period 클래스로 표현할 수 있으며 문자열이나 정수 그리고 빈도를 가지고 생성한다.
p = pd.Period(2007, freq='A-DEC')
p
Period('2007', 'A-DEC')Period 객체는 2007년 1월1일부터 같은 해 12월31일까지의 기간을 표현한다. 이 기간에 정수를 더하거나 빼서 편리하게 정해진 빈도에 따라 기간을 이동시킬 수 있다.
p + 5
Period('2012', 'A-DEC')
p - 2
Period('2005', 'A-DEC')만약 두 기간이 같은 빈도를 가진다면 두 기간의 차는 둘 사이의 간격이 된다.
pd.Period('2014', freq='A-DEC') - p
<7 * YearEnds: month=12>일반적인 기간 범위는 period_range 함수로 생성할 수 있다.
rng = pd.period_range('2000-01-01', '2000-06-30', freq='M')
rng
PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '2000-06'], dtype='period[M]')PeriodIndex 클래스는 순차적인 기간을 저장하며 다른 pandas 자료구조에서 축 색인과 마찬가지로 사용된다.
pd.Series(np.random.randn(6), index=rng)
2000-01 -2.447219
2000-02 -0.468448
2000-03 -0.405767
2000-04 0.527710
2000-05 -0.936528
2000-06 -0.398516
Freq: M, dtype: float64다음과 같은 문자열 배열을 이용해서 PeriodIndex 클래스를 생성하는 것도 가능하다.
values =['2001Q3','2002Q2','2003Q1']
index = pd.PeriodIndex(values, freq='Q-DEC')
index
PeriodIndex(['2001Q3', '2002Q2', '2003Q1'], dtype='period[Q-DEC]')Period의 빈도 변환
기간과 PeriodIndex 객체는 asfreq 메서드를 통해 다른 빈도로 변환할 수 있다. 예를 들어 새해 첫날부터 시작하는 연간 빈도를 월간 빈도로 변환해보자.
p = pd.Period('2007', freq='A-DEC')
p
Period('2007', 'A-DEC')
p.asfreq('M', how='start')
Period('2007-01', 'M')
p.asfreq('M', how='end')
Period('2007-12', 'M')Period('2007', 'A-DEC')는 전체 시간에 대한 커서로 생각할 수 있고 월간으로 다시 나눌 수 있다. 회계연도 마감이 12월이 아닌 경우에는 월간 빈도가 달라진다.
p = pd.Period('2007', freq='A-JUN')
p
Period('2007', 'A-JUN')
p.asfreq('M', 'start')
Period('2006-07', 'M')
p.asfreq('M', 'end')
Period('2007-06', 'M')빈도가 상위 단계에서 하위 단계로 변환되는 경우 상위 기간은 하위 기간이 어디에 속했는지에 따라 결정된다. 예를 들어 A-JUN 빈도일 경우 2007년 8월은 실제로 2008년 기간에 속하게 된다.
p = pd.Period('Aug-2007', 'M')
p.asfreq('A-JUN')
Period('2008', 'A-JUN')모든 PeriodIndex 객체나 시계열은 지금까지 살펴본 내용과 같은 방식으로 변환할 수 있다.
rng = pd.period_range('2006','2009', freq='A-DEC')
rng
PeriodIndex(['2006', '2007', '2008', '2009'], dtype='period[A-DEC]')ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2006 -1.034842
2007 0.584071
2008 0.132220
2009 -0.403721
Freq: A-DEC, dtype: float64위 예제에서 연 빈도는 해당 빈도의 시작 월부터 시작하는 월 빈도로 치환된다. 만일 매 해의 마지막 영업일을 대신 사용하고 싶다면 'B' 빈도를 사용하고 해당 기간의 종료 지점을 지정해서 변환할 수 있다.
ts.asfreq('B', how='end')
2006-12-29 -1.034842
2007-12-31 0.584071
2008-12-31 0.132220
2009-12-31 -0.403721
Freq: B, dtype: float64분기 빈도
분기 데이터는 재정, 금융 및 다른 분야에서 표준으로 사용된다. 많은 분기 데이터는 일반적으로 회계연도의 끝인 12월의 마지막 날이나 마지막 업무일을 기준으로 보고하는데, 2012Q4는 회계연도의 끝이 어딘가에 따라 의미가 달라진다. pandas는 12가지 모든 경우의 수를 지원하며 분기 빈도는 Q-JAN 부터 Q-DEC 까지다.
p = pd.Period('2012Q4', freq='Q-JAN')
p
Period('2012Q4', 'Q-JAN')회계연도 마감이 1월인 경우라면 2012Q4는 11월부터 1월까지가 되고 일간 빈도로 검사할 수 있다.
p.asfreq('D','start')
Period('2011-11-01', 'D')
p.asfreq('D', 'end')
Period('2012-01-31', 'D')이렇게 하여 기간 연산을 매우 쉽게 할 수 있는데, 그 예로 분기 영업마감일의 오후 4시를 가리키는 타임스탬프는 다음과 같이 구할 수 있다.
p4pm = (p.asfreq('B', 'e') - 1).asfreq('T', 's') + 16 * 60
p4pm
Period('2012-01-30 16:00', 'T')
p4pm.to_timestamp()
Timestamp('2012-01-30 16:00:00')period_range를 사용해서 분기 범위를 생성할 수 있다. 연산 역시 동일한 방법으로 수행할 수 있다.
rng = pd.period_range('2011Q3','2012Q4', freq='Q-JAN')
ts = pd.Series(np.arange(len(rng)), index=rng)
ts
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int32new_rng = (rng.asfreq('B','e') -1).asfreq('T', 's') + 16 * 60
ts.index = new_rng.to_timestamp()
ts
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int32타임스탬프와 기간 서로 변환하기
타임스탬프로 색인된 Series와 DataFrame 객체는 to_period 메서드를 사용해서 기간으로 변환 가능하다.
rng = pd.date_range('2000-01-01', periods=3, freq='M')
ts = pd.Series(np.random.randn(3), index=rng)
ts
2000-01-31 -0.102576
2000-02-29 -0.074728
2000-03-31 1.194988
Freq: M, dtype: float64
pts = ts.to_period()
pts
2000-01 -0.102576
2000-02 -0.074728
2000-03 1.194988
Freq: M, dtype: float64여기서 말하는 기간은 겹치지 않는 시간상의 간격을 뜻하므로 주어진 빈도에서 타임스탬프는 하나의 기간에만 속한다. 새로운 PeriodIndex의 빈도는 기본적으로 타임스탬프 값을 통해 추론되지만 원하는 빈도를 직접 지정할 수 있다. 결과에 중복되는 기간이 나오더라도 문제가 되지 않는다.
rng = pd.date_range('1/29/2000', periods=6, freq='D')
ts2 = pd.Series(np.random.randn(6), index=rng)
ts2
2000-01-29 -1.786122
2000-01-30 0.570066
2000-01-31 -1.214033
2000-02-01 -1.678464
2000-02-02 -0.759043
2000-02-03 1.231926
Freq: D, dtype: float64
ts2.to_period('M')
2000-01 -1.786122
2000-01 0.570066
2000-01 -1.214033
2000-02 -1.678464
2000-02 -0.759043
2000-02 1.231926
Freq: M, dtype: float64기간을 타임스탬프로 변환하려면 to_timestamp 메서드를 이용하면 된다.
pts=ts2.to_period()
pts
2000-01-29 -1.786122
2000-01-30 0.570066
2000-01-31 -1.214033
2000-02-01 -1.678464
2000-02-02 -0.759043
2000-02-03 1.231926
Freq: D, dtype: float64
pts.to_timestamp(how='end')
2000-01-29 23:59:59.999999999 -1.786122
2000-01-30 23:59:59.999999999 0.570066
2000-01-31 23:59:59.999999999 -1.214033
2000-02-01 23:59:59.999999999 -1.678464
2000-02-02 23:59:59.999999999 -0.759043
2000-02-03 23:59:59.999999999 1.231926
Freq: D, dtype: float64배열로 PeriodIndex 생성하기
고정된 빈도를 갖는 데이터는 종종 여러 컬럼에 걸쳐 기간에 대한 정보를 함께 저장하기도 한다. 예를 들어 다음 거시경제학(매크로경제학 macroeconomic)데이터셋에는 연도와 분기가 구분된 컬럼에 존재한다.
data = pd.read_csv('examples/macrodata.csv')
data.head()
data.year
0 1959.0
1 1959.0
2 1959.0
3 1959.0
4 1960.0
...
data.quarter
0 1.0
1 2.0
2 3.0
3 4.0
4 1.0
...이 배열을 PeriodIndex에 빈도값과 함께 전달하면 이를 조합해서 DataFrame에서 사용할 수 있는 색인을 만들어낸다.
index = pd.PeriodIndex(year=data.year, quarter = data.quarter, freq = 'Q-DEC')
index
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203)data.index = index
data.head(3)
data.infl
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
...리샘플링과 빈도 변환
리샘플링은 시계열의 빈도를 변화하는 과정을 일컫는다. 상위 빈도의 데이터를 하위 빈도로 집계하는 것을 다운샘플링이라고 하며 반대 과정을 업샘플링이라고 한다. 모든 리샘플링이 이 두 가지 범주에 들어가지는 않는다. 예를 들어 W-WED(수요일을 기준으로 한 주간)를 W-FRI로 변경하는 것은 업샘플링도 다운샘플링도 아니다.
pandas 객체는 resample 메서드를 가지고 있는데, 빈도 변환과 관련된 모든 작업에서 유용하게 사용되는 메서드다. resample은 groupby와 비슷한 API를 가지고 있는데 resample을 호출해서 데이터를 그룹 짓고 요약함수를 적용하는 식이다.
rng = pd.date_range('2000-01-01', periods=100, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2000-01-01 0.215954
2000-01-02 1.873508
2000-01-03 1.292461
2000-01-04 2.494187
2000-01-05 1.614047
...
ts.resample('M').mean()
2000-01-31 0.249094
2000-02-29 -0.047910
2000-03-31 -0.319275
2000-04-30 -0.026816
Freq: M, dtype: float64
ts.resample('M', kind='period').mean()
2000-01 0.249094
2000-02 -0.047910
2000-03 -0.319275
2000-04 -0.026816
Freq: M, dtype: float64resample 메서드 인자
| 인자 | 설명 |
| freq | 원하는 리샘플링 빈도를 가리키는 문자열이나 DateOffset(예:'M', '5min', Second(15)) |
| axis | 리샘플링을 수행할 축, 기본값은 axis=0이다. |
| fill_method | 업샘플링 시 사용할 보간 방법. 'ffill' 과 'bfill'이 있다 . 기본값은 None이다.(보간을 수행하지 않음) |
| closed | 다운샘플링 시 각 간격의 어느 쪽을 포함할지 가리킨다. 'right'와 ' left'가 있고 기본값은 'right'다. |
| label | 다운샘플링 시 집계된 결과의 라벨을 결정한다. 'right' 와 'left'가 있다. 예를 들어 9:30에서 9:35까지 5분 간격이 있을 때 라벨은 9:30 혹은 9:35가 될 수 있다. 기본값은 'right'다 (이 경우에는 9:35가 된다.) |
| loffset | 나눤그룹의 라벨에 맞추기 위한 오프셋, '-1s' / Second(-1)은 집계된 라벨을 1초 앞당긴다. |
| limit | 보간법을 사용할 때 보간을 적용할 최대 기간 |
| kind | 기간('period')별 혹은 타임스탬프('timestamp')별로 집계할 것인지 구분. 기본값은 시계열 색인의 종류와 같다. |
| convention | 기간을 리샘플링할 때 하위 빈도 기간에서 상위 빈도로 변환 시의 방식('start' 혹은 'end'). 기본값은 'end'다. |
다운샘플링
시계열 데이터를 규칙적인 하위 빈도로 집계하는 일은 특별한 일이 아니다. 집계할 데이터는 고정 빈도를 가질 필요가 없으며 잘라낸 시계열 조각의 크기를 원하는 빈도로 정의한다. 예를 들어 'M'이나 'BM' 같은 월간 빈도로 변환하려면 데이터를 월 간격으로 나눠야 한다. 각 간격은 한쪽이 열려 있게 되는데, 이 말은 하나의 간격에서 양끝 중 한쪽만 포함된다는 뜻이다. 그러면 각 간격의 모음이 전체 시계열이 된다. resample을 사용해서 데이터를 다운샘플이할 때 고려해야할 사항이 몇 가지 있다.
● 각 간격의 양끝 중에서 어느 쪽을 닫아둘 것인가
● 집계하려는 구간의 라벨을 간격의 시작으로 할지 끝으로 할지 여부
rng = pd.date_range('2000-01-01', periods=12, freq='T')
ts = pd.Series(np.arange(12), index=rng)
ts
2000-01-01 00:00:00 0
2000-01-01 00:01:00 1
2000-01-01 00:02:00 2
2000-01-01 00:03:00 3
2000-01-01 00:04:00 4
2000-01-01 00:05:00 5
2000-01-01 00:06:00 6
2000-01-01 00:07:00 7
2000-01-01 00:08:00 8
2000-01-01 00:09:00 9
2000-01-01 00:10:00 10
2000-01-01 00:11:00 11
Freq: T, dtype: int32이 데이터를 5분 단위로 묶어서 각 그룹의 합을 집계해보자
ts.resample('5min', closed='right').sum()
1999-12-31 23:55:00 0
2000-01-01 00:00:00 15
2000-01-01 00:05:00 40
2000-01-01 00:10:00 11
Freq: 5T, dtype: int32인자로 넘긴 빈도는 5분 단위로 증가하는 그룹의 경계를 정의한다. 기본적으로 시작값을 그룹의 왼쪽에 포함시키므로 00:00의 값은 첫 번째 그룹의 00:00 부터 00:05 까지의 값을 집계한다. closed='right'를 넘기면 시작값을 그룹의 오른쪽에 포함시킨다.
결과로 반환된 시계열은 각 그룹의 왼쪽 타임스탬프가 라벨로 지정되었다. label='right'를 넘겨서 각 그룹의 오른쪽 값을 라벨로 사용할 수 있다.
ts.resample('5min',closed='right', label='right').sum()
2000-01-01 00:00:00 0
2000-01-01 00:05:00 15
2000-01-01 00:10:00 40
2000-01-01 00:15:00 11
Freq: 5T, dtype: int32반환된 결과의 색인을 특정 크기만큼 이동시키고 싶은 경우, 즉 그룹의 오른쪽 끝에서 1초를 빼서 타임스탬프가 참조하는 간격을 좀 더 명확히 보여주고 싶은 경우에는 loffset 메서드에 문자열이나 날짜 오프셋을 넘기면 된다.
ts.resample('5min', closed='right', label='right', loffset ='-1s').sum()1999-12-31 23:59:59 0
2000-01-01 00:04:59 15
2000-01-01 00:09:59 40
2000-01-01 00:14:59 11
Freq: 5T, dtype: int32loffset 대신 반환된 결과에 shift 메서드를 사용해서 같은 결과를 얻을 수 있다.
OHLC 리샘플링
금융 분야에서 시계열 데이터를 집계하는 아주 흔한 방식은 각 버킷에 대해 4가지 값을 계산하는 것이다. 이 4가지 값은 시가 open, 고가 high, 저가 low, 종가 close이며, 이를 OHLC Open-High-Low-Close라고 한다. how='ohlc'를 넘겨서 한 번에 이 값을 담고 있는 컬럼을 가지는 DataFrame을 얻을 수 있다.
ts.resample('5min').ohlc()
업샘플링과 보간
하위 빈도에서 상위 빈도로 변환할 때는 집계가 필요하지 않다. 주간 데이터를 담고 있는 DataFrame을 살펴보자.
frame = pd.DataFrame(np.random.randn(2,4), index=pd.date_range('1/1/2000', periods=2, freq='W-WED'),
columns=['Colorado','Texas','New York','Ohio'])
frame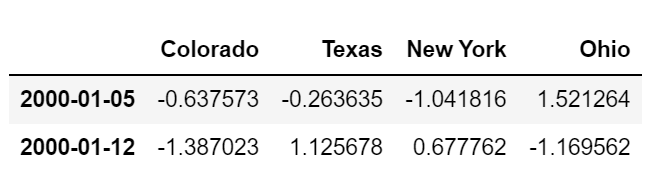
이 데이터에 요약함수를 사용하면 그룹당 하나의 값이 들어가고 그 사이에 결측치가 들어간다. asfreq 메서드를 이용해서 어떤 요약함수도 사용하지 않고 상위 빈도로 리샘플링해보자.
df_daily = frame.resample('D').asfreq()
df_daily
수요일이 아닌 요일에는 이전 값을 채워서 보간을 수행한다고 가정하자. fillna와 reindex 메서드에서 사용했던 보간 메서드를 리샘플링에서도 사용할 수 있다.
frame.resample('D').ffill()
limit 옵션을 사용해서 보간법을 적용할 범위를 지정하는 것도 가능하다.
frame.resample('D').ffill(limit=2)
특히 새로운 날짜 색인은 이전 색인과 겹쳐질 필요가 전혀 없다.
frame.resample('W-THU').ffill()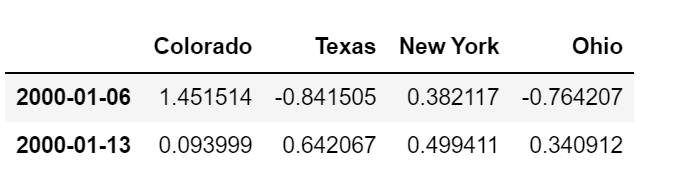
기간 리샘플링
기간으로 색인되 데이터를 리샘플링것은 타임스탬프와 유사하다.
frame = pd.DataFrame(np.random.randn(24,4),
index=pd.period_range('1-2000','12-2001',freq='M'),
columns=['Colorado', 'Texas','New York','Ohio'])
frame[:5]
annual_frame = frame.resample('A-DEC').mean()
annual_frame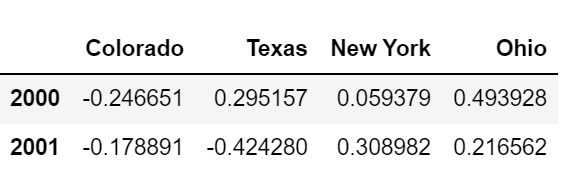
업샘플링은 asfreq 메서드처럼 리샘플링하기 전에 새로운 빈도에서 구간의 끝을 어느 쪽에 두어야 할지 미리 결정해야 한다. convention 인자의 기본값은 'start'지만 'end'로 지정할 수도 있다.
annual_frame.resample('Q-DEC').ffill()
annual_frame.resample('Q-DEC', convention= 'end').ffill()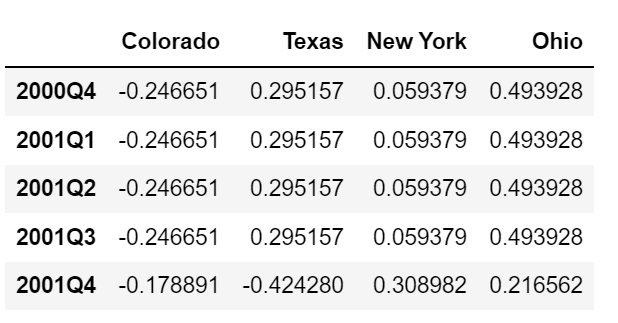
기간의 업샘플링과 다운샘플링은 좀 더 엄격하다.
● 다운샘플링의 경우 대상 빈도는 반드시 원본 빈도의 하위 기간이어야 한다.
● 업샘플링의 경우 대상 빈도는 반드시 원본 빈도의 상위 기간이어여 한다.
위 조건을 만족하지 않으면 예외가 발생한다. 이 예외는 주로 분기, 연간, 주간 빈도에서 발생하는데, 예를 들어 Q-MAR로 정의된 기간은 A-MAR, A-JUN, A-SEP, A-DEC로만 이루어져 있다.
annual_frame.resample('Q-MAR').ffill()