파이썬 모델링 라이브러리, Patsy
파이썬 모델링 라이브러리,Patsy
pandas와 모델 코드의 인터페이스
Patsy를 이용해서 모델 생성하기
● Patsy 용법으로 데이터 변환하기
● 범주형 데이터와 Patsy
모델 개발의 일반적인 흐름은 데이터를 불러오고 정제하는 과정은 pandas를 이용하고 그 후 모델 개발을 위해 모델링 라이브러리로 넘어가게 된다. 모델을 개발하는 과정에서 중요한 단계는 특징을 선택하고 추출하는 피처 엔지니어링인데 원시 데이터셋으로부터 모델링에서 유용할 수 있는 정보를 추출하는 변환이나 분석 과정을 일컫는다.
pandas와 다른 분석 라이브러리는 주로 Numpy 배열을 사용해서 연계할 수 있다. DataFrame을 Numpy 배열로 변환하려면 .values 속성을 이용한다.
data = pd.DataFrame({'x0':[1,2,3,4,5],
'x1':[0.01, -0.01, 0.25, -4.1, 0.],
'y':[-1.5, 0., 3.6, 1.3, -2.]})
data
data.columns
Index(['x0', 'x1', 'y'], dtype='object')
data.values
array([[ 1. , 0.01, -1.5 ],
[ 2. , -0.01, 0. ],
[ 3. , 0.25, 3.6 ],
[ 4. , -4.1 , 1.3 ],
[ 5. , 0. , -2. ]])다시 DataFrame으로 되돌리려면 앞서 공부했던 것처럼 2차원 ndarray와 필요하다면 컬럼이름 리스트를 넘겨서 생성할 수 있다.
df2 = pd.DataFrame(data.values, columns=['one','two','three'])
df
.values 속성은 데이터가 한 가지 타입(예를 들면 모두 숫자형)으로 이루어져 있다는 가정 하에 사용된다. 만약 데이터 속성이 한 가지가 아니라면 파이썬 객체의 ndarray가 반환될 것이다.
df3 = data.copy()
df3['strings'] = ['a','b','c','d','e']
df3df3.values
array([[1, 0.01, -1.5, 'a'],
[2, -0.01, 0.0, 'b'],
[3, 0.25, 3.6, 'c'],
[4, -4.1, 1.3, 'd'],
[5, 0.0, -2.0, 'e']], dtype=object)어떤 모델은 전체 컬럼 중 일부만 사용하고 싶은 경우도 있을 것이다. 이 경우 loc을 이용해서 values 속성에 접근하기 바란다.
model_cols =['x0','x1']
data.loc[:, model_cols].values
array([[ 1. , 0.01],
[ 2. , -0.01],
[ 3. , 0.25],
[ 4. , -4.1 ],
[ 5. , 0. ]])어떤 라이브러리는 pandas를 직접 지원하기도 하는데 위에서 설명한 과정을 자동으로 처리해준다. DataFrame에서 Numpy 배열로 모델 인자의 이름을 출력 테이블이나 Series의 컬럼으로 추가한다. 아니라면 이런 메타 데이터 관리를 수동으로 직접 해야 한다.
data['category'] = pd.Categorical(['a','b','a','a','b'], categories=['a','b'])
data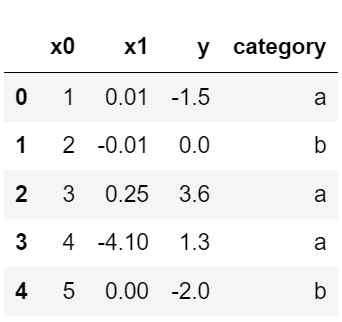
만일 'category' 컬럼을 더미값으로 치환하고 싶다면 더미값을 생성하고 'category' 컬럼을 삭제한 다음 결과와 합쳐야 한다.
dummies = pd.get_dummies(data.category, prefix ='category')
dummies
data_with_dummies = data.drop('category', axis=1).join(dummies)
data_with_dummies
Patsy를 이용해서 모델 생성하기
Patsy(팻시)는 통계 모델(특히 선형 모델)을 위한 파이썬 라이브러리이며 R이나 S 통계 프로그래밍 언어에서 사용하는 수식 문법과 비슷한 형식의 문자열 기반 '수식 문법'을 제공한다.
Patsy는 통계 모델에서 선형 모델을 잘 지원하므로 이해를 돕기 위해 주요 기능 중 일부만 살펴보도록 하자. Patsy의 수식 문법은 다음과 같은 특수한 형태의 문자열이다.
y ~ x0 + x1
a + b 문법은 a와 b를 더하라는 의미가 아니라 모델을 위해 생성된 배열을 설계하는 용법이다. patsy.dmatrices 함수는 수식 문자열과 데이터셋(DataFrame 또는 배열의 사전)을 함께 받아 선형 모델을 위한 설계 배열을 만들어낸다.
data = pd.DataFrame({'x0':[1,2,3,4,5],
'x1':[0.01, -0.01, 0.25, -4.1, 0.],
'y':[-1.5, 0., 3.6, 1.3, -2.]})
data
import patsy
y, X = patsy.dmatrices('y~ x0+x1', data)
y
DesignMatrix with shape (5, 1)
y
-1.5
0.0
3.6
1.3
-2.0
Terms:
'y' (column 0)
X
DesignMatrix with shape (5, 3)
Intercept x0 x1
1 1 0.01
1 2 -0.01
1 3 0.25
1 4 -4.10
1 5 0.00
Terms:
'Intercept' (column 0)
'x0' (column 1)
'x1' (column 2)Patsy의 DesignMatrix 인스턴스는 몇 가지 추가 데이터가 포함된 Numpy ndarray로 볼 수 있다.
np.asarray(y)
array([[-1.5],
[ 0. ],
[ 3.6],
[ 1.3],
[-2. ]])np.asarray(X)
array([[ 1. , 1. , 0.01],
[ 1. , 2. , -0.01],
[ 1. , 3. , 0.25],
[ 1. , 4. , -4.1 ],
[ 1. , 5. , 0. ]])여기서 Intercept는 최소자승회귀와 같은 선형 모델을 위한 표현이다. 모델에 0을 더해서 intercept (절편)를 제거할 수 있다.
patsy.dmatrices('y ~ x0 + x1 + 0', data)[1]
DesignMatrix with shape (5, 2)
x0 x1
1 0.01
2 -0.01
3 0.25
4 -4.10
5 0.00
Terms:
'x0' (column 0)
'x1' (column 1)Pasty 객체는 최소자승회귀분석을 위해 numpy.linalg.lstsq 같은 알고리즘에 바로 넘길 수 있도 있다.
coef, resid, _, _ = np.linalg.lstsq(X,y)모델 메타데이터는 design_info 속성을 통해 얻을 수 있는데 예를 들면 모델의 컬럼명을 피팅된 항에 맞추어 Series를 만들어낼 수 도 있다.
coef
array([[ 0.31290976],
[-0.07910564],
[-0.26546384]])coef = pd.Series(coef.squeeze(), index=X.design_info.column_names)Patsy 용법으로 데이터 변환하기
파이썬 코드를 Patsy 용법과 섞어서 사용할 수도 있는데, Patsy 문법을 해석하는 과정에서 해당함수를 찾아 실행해준다.
y, X = patsy.dmatrices('y ~ x0 + np.log(np.abs(x1) + 1)', data)
X
DesignMatrix with shape (5, 3)
Intercept x0 np.log(np.abs(x1) + 1)
1 1 0.00995
1 2 0.00995
1 3 0.22314
1 4 1.62924
1 5 0.00000
Terms:
'Intercept' (column 0)
'x0' (column 1)
'np.log(np.abs(x1) + 1)' (column 2)자주 쓰이는 변수 변환으로는 표준화(평균0, 분산1)와 센터링(평균값을 뺌)이 있는데 Pasty에는 이런 목적을 위한 내장 함수가 존재한다.
y, X = patsy.dmatrices('y ~ standardize(x0) + center(x1)', data)
X
DesignMatrix with shape (5, 3)
Intercept standardize(x0) center(x1)
1 -1.41421 0.78
1 -0.70711 0.76
1 0.00000 1.02
1 0.70711 -3.33
1 1.41421 0.77
Terms:
'Intercept' (column 0)
'standardize(x0)' (column 1)
'center(x1)' (column 2)모델링 과정에서 모델을 어떤 데이터셋에 피팅하고 그다음에 다른 모델에 기반하여 평가해야 하는 경우가 있다. 이는 홀드-아웃 hold-out 이거나 신규 데이터가 나중에 관측되는 경우다. 센터링이나 표준화 같은 변환을 적용하는 경우 새로운 데이터에 기반하여 예측하기 위한 용도로 모델을 사용한다면 주의해야 한다. 이를 상태를 가지는 stateful 변환이라고 하는데 새로운 데이터셋을 변경하기 위해 원본 데이터의 표준편차아 평균 같은 통계를 사용해야 하기 때문이다.
patsy.build_design_matrices 함수는 입력으로 사용되는 원본 데이터셋에서 저장한 정보를 사용해서 출력 데이터를 만들ㅇ어내는 변환에 적용할 수 있는 함수다.
new_data = pd.DataFrame({'x0':[6,7,8,9],
'x1':[3.1, -0.5, 0, 2.3],
'y':[1,2,3,4]})
new_data
new_x = patsy.build_design_matrices([X.design_info], new_data)
new_x
[DesignMatrix with shape (4, 3)
Intercept standardize(x0) center(x1)
1 2.12132 3.87
1 2.82843 0.27
1 3.53553 0.77
1 4.24264 3.07
Terms:
'Intercept' (column 0)
'standardize(x0)' (column 1)
'center(x1)' (column 2)]Patsy 문법에 더하기 기호(+)는 덧셈이 아니므로 데이터셋에서 이름으로 컬럼을 추가하고 싶다면 I라는 특수한 함수로 둘러싸야 한다.
y,X = patsy.dmatrices('y ~ I(x0 + x1)', data)
X
DesignMatrix with shape (5, 2)
Intercept I(x0 + x1)
1 1.01
1 1.99
1 3.25
1 -0.10
1 5.00
Terms:
'Intercept' (column 0)
'I(x0 + x1)' (column 1)Patsy는 patsy.builtins 모듈 내에 여러 가지 변환을 위한 내장 함수들을 제공한다.
범주형 데이터와 Patsy
비산술 데이터는 여러 가지 형태의 모델 설계 배열로 변환될 수 있다.
Patsy에서 비산술 용법을 사용하면 기본적으로 더미 변수로 변환된다. 만약 intercept가 존재한다면 공선성을 피하기 위해 레벨 중 하나는 남겨두게 된다.
data = pd.DataFrame({
'key1':['a','a','b','b','a','b','a','b'],
'key2':[0,1,0,1,0,1,0,0],
'v1':[1,2,3,4,5,6,7,8],
'v2':[-1,0,2.5,-0.5,4.0, -1.2,0.2,-1.7]
})
y, X = patsy.dmatrices('v2 ~ key1', data)
X
DesignMatrix with shape (8, 2)
Intercept key1[T.b]
1 0
1 0
1 1
1 1
1 0
1 1
1 0
1 1
Terms:
'Intercept' (column 0)
'key1' (column 1)모델에서 intercept를 생략하면 각 범주값의 컬럼은 모델 설계 배열에 포함된다.
y, X = patsy.dmatrices('v2 ~ key1 + 0', data)
X
DesignMatrix with shape (8, 2)
key1[a] key1[b]
1 0
1 0
0 1
0 1
1 0
0 1
1 0
0 1
Terms:
'key1' (columns 0:2)산술 컬럼은 C 함수를 이용해서 범주향으로 해석할 수 있다.
y, X = patsy.dmatrices('v2 ~ C(key2)', data)
X
DesignMatrix with shape (8, 2)
Intercept C(key2)[T.1]
1 0
1 1
1 0
1 1
1 0
1 1
1 0
1 0
Terms:
'Intercept' (column 0)
'C(key2)' (column 1)모델에서 여러 범주형 항을 사용한다면 ANOVA analysis of varaince(분산분석) 모델에서 처럼 key1:key2 같은 용법을 사용할 수 있게 되므로 더 복잡해진다.
data['key2'] = data['key2'].map({0:'zero', 1:'one'})
data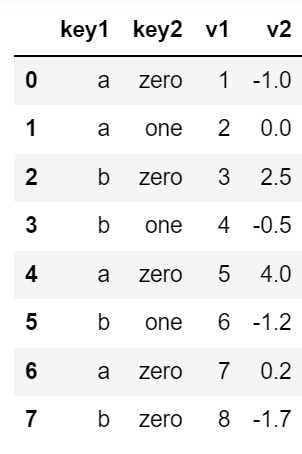
y, X = patsy.dmatrices('v2 ~ key1 + key2', data)
XDesignMatrix with shape (8, 3)
Intercept key1[T.b] key2[T.zero]
1 0 1
1 0 0
1 1 1
1 1 0
1 0 1
1 1 0
1 0 1
1 1 1
Terms:
'Intercept' (column 0)
'key1' (column 1)
'key2' (column 2)y, X = patsy.dmatrices('v2 ~ key1 + key2 + key1:key2', data)
X
DesignMatrix with shape (8, 4)
Intercept key1[T.b] key2[T.zero] key1[T.b]:key2[T.zero]
1 0 1 0
1 0 0 0
1 1 1 1
1 1 0 0
1 0 1 0
1 1 0 0
1 0 1 0
1 1 1 1
Terms:
'Intercept' (column 0)
'key1' (column 1)
'key2' (column 2)
'key1:key2' (column 3)Patsy는 특정 순서에 따라 데이터를 변환하는 방법을 포함하여 범주형 데이터를 변환하는 여러 가지 방법을 제공한다.
https://patsy.readthedocs.io/en/latest/index.html
patsy - Describing statistical models in Python — patsy 0.5.1+dev documentation
© Copyright 2011-2015, Nathaniel J. Smith Revision 4c613d0a.
patsy.readthedocs.io