
pandas에서 seaborn으로 그래프 그리기
pandas에서 seaborn으로 그래프 그리기
pandas는 Series와 DataFrame 객체를 간단하게 시각화할 수 있는 내장 메서드를 제공한다. 다른 라이브러리로는 마이클 와스콤 Michael Waskom이 만든 통계 그래픽 라이브러리인 seaborn이 있다. seaborn은 흔히 사용하는 다양한 시각화 패턴을 쉽게 구현할 수 있도록 도와준다. seaborn 라이브러리를 임포트하면 더 나은 가독성과 미려함을 위해 matplotlib의 기본 컬럼 스킴과 플롯 스타일을 변경한다.
https://seaborn.pydata.org/examples/index.html
Example gallery — seaborn 0.11.2 documentation
seaborn.pydata.org
https://seaborn.pydata.org/api.html
API reference — seaborn 0.11.2 documentation
Independently manipulate the h, l, or s channels of a color.
seaborn.pydata.org
선 그래프
Series와 DataFrame은 둘다 plot 메서드를 이용해 다양한 형태의 그래프를 생성할 수 있다. 기본적으로 plot메서드는 선그래프를 생성한다.
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
s.plot()
Series 객체의 색인은 matplotlib에서 그래프를 생성할 때 x축으로 해석되며 use_index =False 옵션을 넘겨서 색인을 그래프의 축으로 사용하는 것을 막을 수 있다. X축의 눈금과 한계는 xticks와 xlim 옵션으로 조절할 수 있으며 y축 역시 yticks와 ylim 옵션으로 조절할 수 있다.
대부분의 pandas 그래프 메서드는 부수적으로 ax 인자를 받는데, 이 인자는 matplotlib의 서브플롯 객체가 될 수 있다. 이를 이용해 그리드 배열 상에서 서브플롯의 위치를 좀 더 유연하게 가져갈 수 있다.
DataFrame의 plot 메서드는 하나의 서브플롯 안에 각 컬럼별로 선그래프를 그리고 자동적으로 범례를 생성한다.
df = pd.DataFrame(np.random.randn(10, 4).cumsum(0),
columns=['A','B','C','D'],
index = np.arange(0,100, 10))
plot 속성에는 다양한 종류의 그래프 패밀리가 존재한다. 예를 들어 df.plot()은 df.plot.line()과 동일하다. plot 메서드에 전달할 수 있는 부수적인 키워드 인자들은 그대로 matplotlib의 함수로 전달된다. 따라서 matplotlib API를 자세히 공부하면 더 다양한 방식으로 그래프를 꾸밀 수 있다.
Series.plot 메서드 인자
| 인자 | 설명 |
| label | 그래프의 범례 이름 |
| ax | 그래프를 그릴 matplotlib의 서브플롯 객체. 만약 아무것도 넘어오지 않으면 현재 활성화되어 있는 matplotlib의 서브플롯을 사용한다. |
| style | matplotlib에 전달할 'ko--' 같은 스타일 문자열 |
| alpha | 그래프 투명도(0부터 1까지) |
| kind | 그래프 종류. 'area', 'bar', 'barh', 'density', 'hist', 'kde', 'line', 'pie' |
| logy | y축에 대한 로그 스케일링 |
| use_index | 객체의 색인을 눈금 이름으로 사요할지 여부 |
| rot | 눈금 이름을 로테이션(0부터 360까지) |
| xticks | x축으로 사용할 값 |
| yticks | y축으로 사용할 값 |
| xlim | x축 한계(예:[0, 10]) |
| ylim | y축 한계 |
| grid | 축의 그리드를 표시할지 여부(기본값은 켜기) |
DataFrame에는 컬럼을 쉽게 다루기 위한 몇가지 옵션이 있는데, 예를 들어 모든 칼럼을 같은 서브플롯에 그릴것인지 아니면 각각의 서브플롯을 따로 만들 것인지 지정할 수 있다.
DataFrame의 plot메서드 인자
| 인자 | 설명 |
| subplots | 각 DataFrame의 칼럼을 독립된 서브플롯에 그린다. |
| sharex | subplots=True인 경우 같은 x축을 공유하고 눈금과 한계를 연결한다. |
| sharey | subplots =True인 경우 같은 y축을 공유한다. |
| figsize | 생성될 그래프의 크기를 튜플로 지정한다. |
| title | 그래프의 제목을 문자열로 지정한다. |
| legend | 서브플롯의 범례를 추가한다(기본값은 True) |
| sort_columns | 칼럼을 알파벳 순서로 그린다. 기본값은 존재하는 칼럼 순서 |
막대그래프
plot.bar() 와 plot.barh()는 각각 수직막대그래프와 수평막대그래프를 그린다. 이 경우 Series 또는 DataFrame의 색인은 수직막대그래프(bar)인 경우 x 눈금, 수평막대그래프(barh)인 경우 y눈금으로 사용된다.
fig, axes = plt.subplots(2,1)
data = pd.Series(np.random.rand(16), index = list('abcdefghijklmnop'))
data.plot.bar(ax= axes[0], color='k', alpha = 0.7)
data.plot.barh(ax=axes[1], color='k', alpha=0.7)막대 그래프를 그릴 때 유용한 방법은 Series의 value_counts 메서드 (s.value_
counts().plot.bar())를 이용해서 값의 빈도를 그리는 것이다.
DataFrame에서 막대그래프는 각 로우의 값을 함께 묶어서 하나의 그룹마다 각각의 막대를 보여준다.
df = pd.DataFrame(np.random.rand(6,4),
index=['one','two','three','four','five','six'],
columns = pd.Index(['A','B','C','D'], name = 'genus'))
df.plot.bar()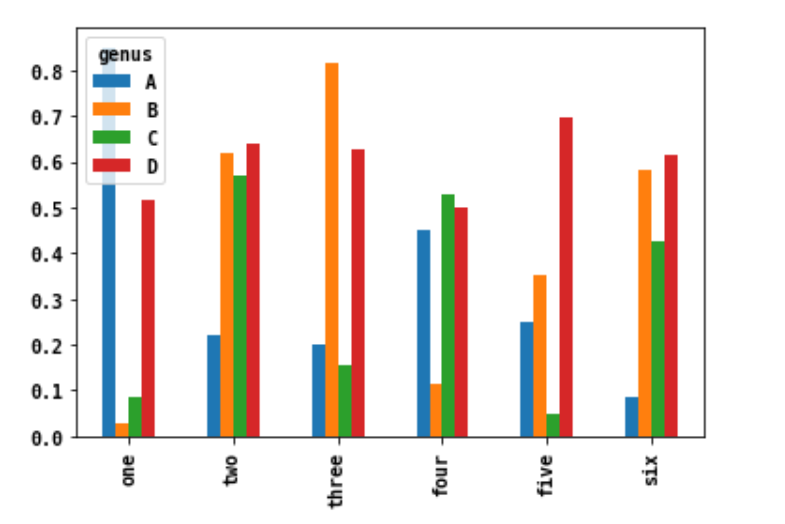
df.plot.barh(stacked=True, alpha=0.5)
팁 데이터에서 요일별 파티 숫자를 뽑고 파티 숫자 대비 팁 비율을 보여주는 막대그래프를 그려보자.
tips = pd.read_csv('examples/tips.csv')
tips.head()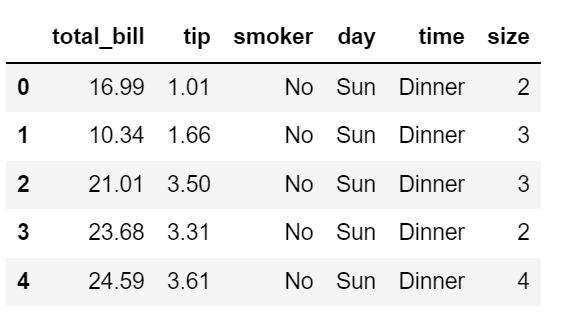
party_counts = pd.crosstab(tips['day'], tips['size'])
party_counts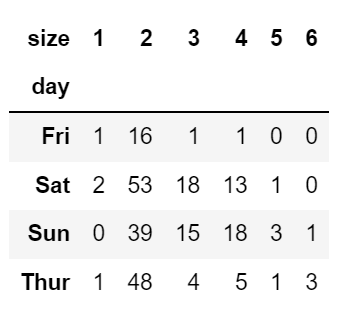
1인과 6인 파티는 제외
party_counts = party_counts.loc[:, 2:5]
party_counts
각 로우의 합이 1이 되도록 정규화하고 그래프를 그려보자
party_pcts = party_counts.div(party_counts.sum(1), axis=0)
party_pcts
party_pcts.plot.bar()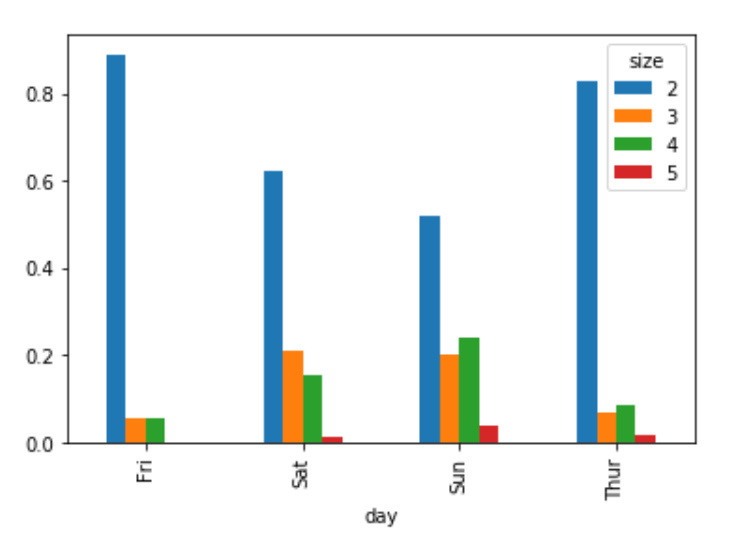
이 데이터에서 파티의 규모는 주말에 커지는 경향이 있음을 알 수 있다.
그래프를 그리기 전에 요약을 해야 하는 데이터는 seaborn 패키지를 이용하면 훨씬 간단하게 처리할 수 있다.
이번에는 seaborn 패키지로 팁 데이터를 다시 그려보자
import seaborn as sns
tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])
tips.head()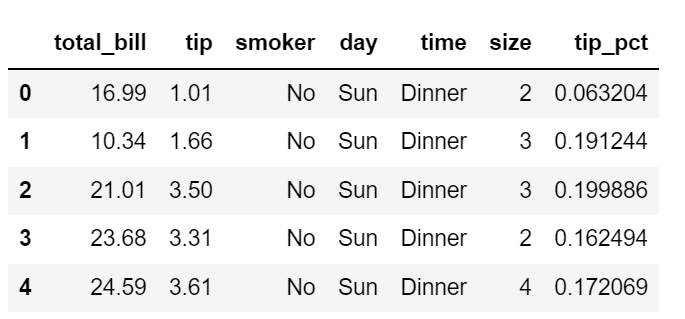
sns.barplot(x='tip_pct', y='day', data = tips, orient='h')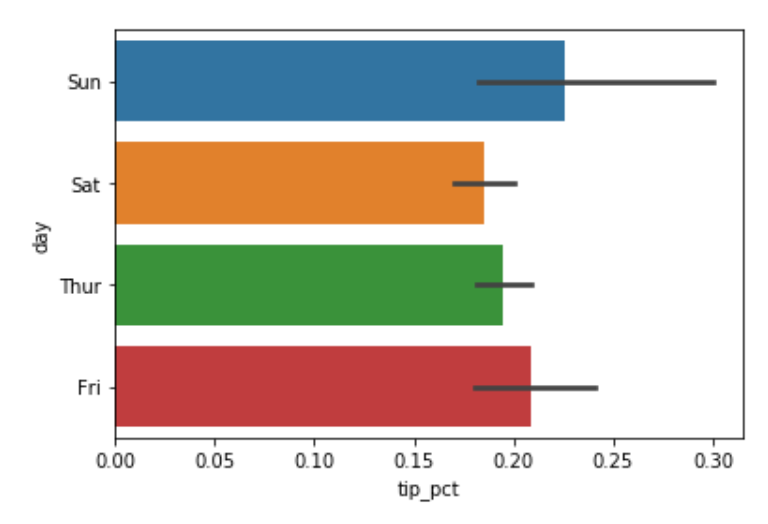
seaborn 플로팅 함수의 data 인자는 pandas의 DataFrame을 받는다. 다른 인자들은 컬럼 이름을 참조한다. day 컬럼의 각 값에 대한 데이터는 여럿 존재하므로 tip_pct의 평균값으로 막대그래프를 그린다. 막대그래프 위에 검은 선은 95%의 신뢰구간을 나타낸다.(이 값은 옵션으로 설정 가능하다.)
seaborn.barplot 메서드의 hue 옵션을 이용하여 추가 분류에 따라 나눠 그릴 수 있다
sns.barplot(x='tip_pct', y='day', hue='time', data=tips, orient='h')
seaborn 라이브러리는 자동으로 기본 색상 팔레트, 그래프 배경, 그리드 선 색상 같은 꾸밈새를 변경한다.
seaborn.set 메서드를 이용해서 이런 꾸밈새를 변경할 수 있다.
sns.set(style ="whitegrid")
히스토그램과 밀도 그래프
히스토그램은 막대그래프의 한 종류로, 값들의 빈도를 분리해서 보여준다. 데이터 포인트는 분리되어 고른 간격의 막대로 표현되며 데이터의 숫자가 막대의 높이로 표현된다.
앞에서 살펴본팁 데이터를 사용해서 전체 결제금액 대비 팁 비율을 Series의 plot.hist 메서드를 사용해서 만들어보자
tips['tip_pct'].plot.hist(bins=50)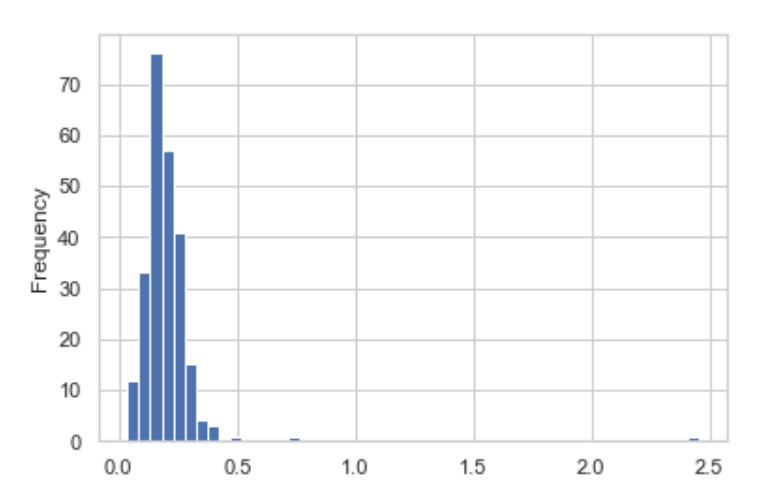
이와 관련 있는 다른 그래프로 밀도 그래프가 있는데 밀도 그래프는 관찰값을 사용해서 추정되는 연속된 확률 분포를 그린다. 일반적인 과정은 kernel메서드를 잘 섞어서 이 분포를 근사하는 방법인데 이보다 단순한 정규 분포다.
그래서 밀도 그래프는 KDE kernel Density Estimate(커넬밀도 추정) 그래프라고도 알려져 있다. plot.kde를 이용해서 밀도 그래프를 표준 KDE 형식으로 생성한다.
tips['tip_pct'].plot.density()
seaborn 라이브러리의 displot메서드를 이용해서 히스토그램과 밀도 그래프를 한 번에 손 쉽게 그릴 수 있다. 예를 들어 두 개의 다른 표준정규분포로 이루어진 양봉분포 bimodal distribution 를 생각해보자
comp1 = np.random.normal(0, 1, size=200)
comp2 = np.random.normal(10, 2, size=200)
values = pd.Series(np.concatenate([comp1, comp2]))
sns.distplot(values, bins=100, color='k')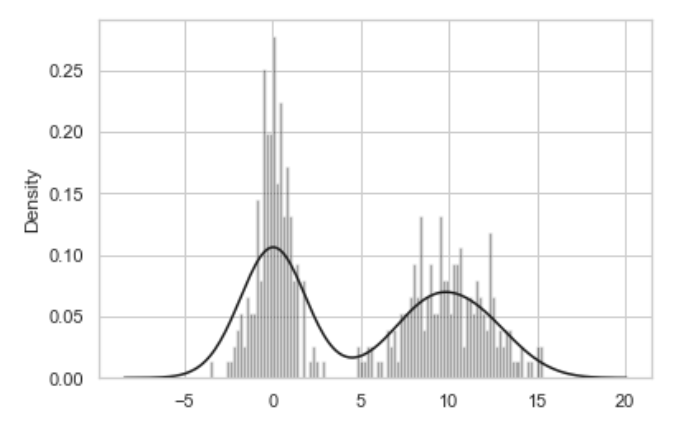
산포도
산포도 scatter plot, point plot는 두 개의 1차원 데이터 묶음 간의 관계를 나타내고자 할 때 유용한 그래프다.
statsmodels 프로젝트에서 macrodata 데이터 묶음을 불러론 다음 몇 가지 변수를 선택하고 로그차를 구해보자
macro = pd.read_csv('examples/macrodata.csv')
macro.head(3)
data = macro[['cpi', 'm1', 'tbilrate', 'unemp']]
data.head(3)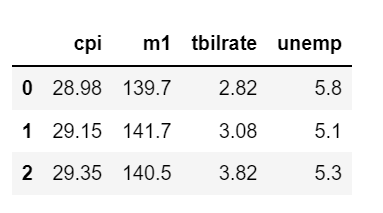
trans_data = np.log(data).diff().dropna()
trans_data[-5:]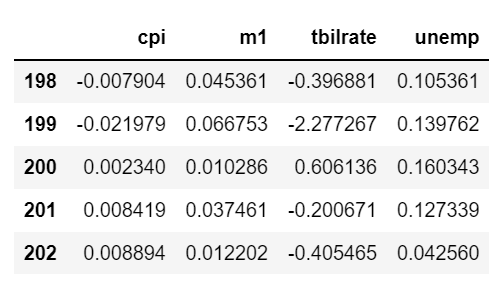
seaborn 라이브러리의 regplot 메서드를 이용해서 산포도와 선형회귀곡선을 함께 그릴 수 있다.
sns.regplot('m1', 'unemp', data=trans_data)
plt.title('Changes in log %s versus log %s' % ('m1','unemp'))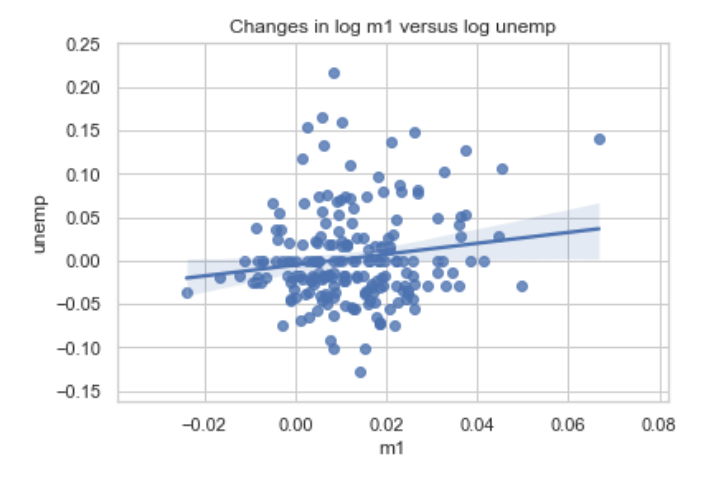
탐색 데이터 분석에서는 변수 그룹 간의 모든 산포도를 살펴보는 일이 매우 유용한데, 이를 짝지은 그래프 또는 산포도 행렬이라고 부른다.
이런 그래프를 직접 그리는 과정은 다소 복잡하기 때문에 seaborn에서는 pairplot 함수를 제공하여 대각선을 따라 각 변수에 대한 히스토그램이나 밀도 그래프도 생성할 수 있다.
sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha':0.2})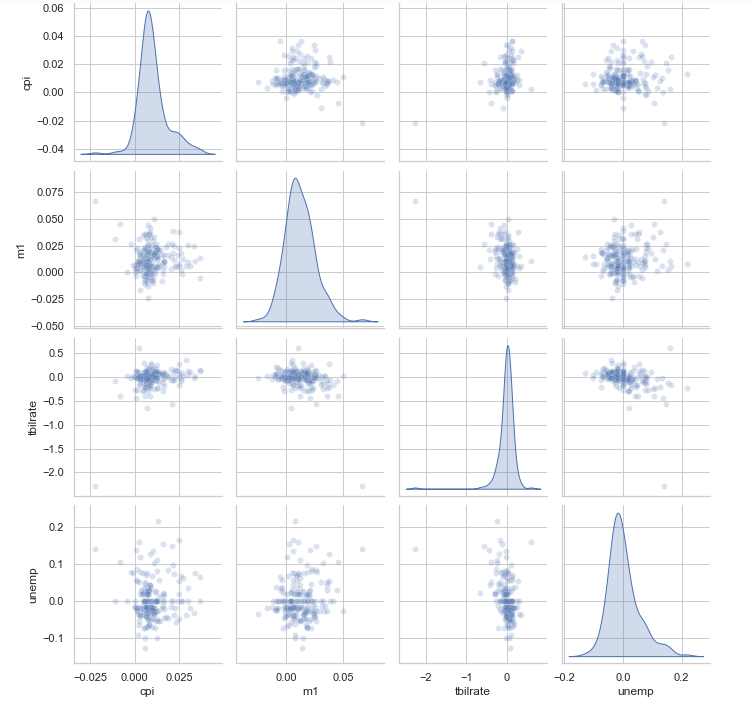
plot_kws 인자는 각각의 그래프에 전달할 개별 설정값을 지정한다. 설정 옵션에 관한 자세한 내용은 seaborn.pairplot문서를 참고하자.
https://seaborn.pydata.org/generated/seaborn.pairplot.html#seaborn.pairplot
seaborn.pairplot — seaborn 0.11.2 documentation
Dictionaries of keyword arguments. plot_kws are passed to the bivariate plotting function, diag_kws are passed to the univariate plotting function, and grid_kws are passed to the PairGrid constructor.
seaborn.pydata.org
패싯 그리드와 범주형 데이터
추가적인 그룹 차원을 가지는 데이터는 어떻게 시각화해야 할까?
다양한 범주형 값을 가지는 데이터를 시각화하는 한 가지 방법은 패싯 그리드를 이용하는 것이다.
seaborn은 factorplot이라는 유용한 내장 함수를 제공하여 다양한 면을 나타내는 그래프를 쉽게 그릴 수 있게 도와준다.
sns.factorplot(x='day',y ='tip_pct', hue='time', col='smoker', kind='bar',data =tips[tips.tip_pct < 1])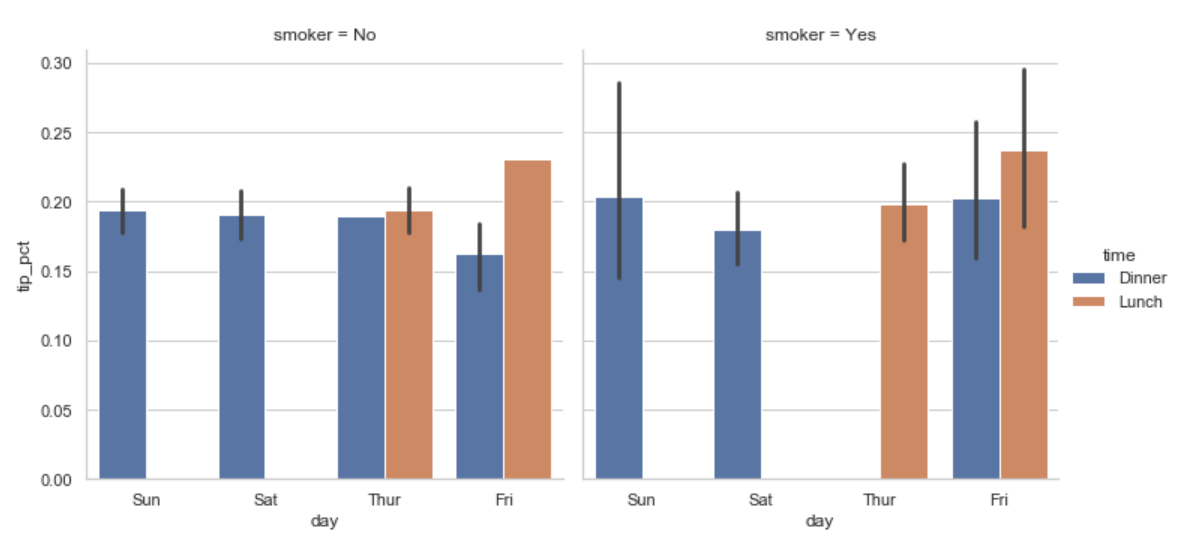
time'으로 그룹을 만드는 대신 패싯 안에서 막대그래프의 색상을 달리해서 보여줄 수 있다.
또한 패싯 그리드에 time값에 따른 그래프를 추가할 수 도 있다.
sns.factorplot(x='day', y='tip_pct', row='time', col='smoker', kind='bar', data=tips[tips.tip_pct < 1])
factorplot은 보여주고자 하는 목적에 어울리는 다른 종류의 그래프도 함께 지원한다.
예를 들어 중간값과 사분위 그리고 특잇값을 보여주는 상자그림box plot이 효과적인 시각화 방법일 수도 있다
sns.factorplot(x='tip_pct', y='day', kind='box', data=tips[tips.tip_pct < 0.5])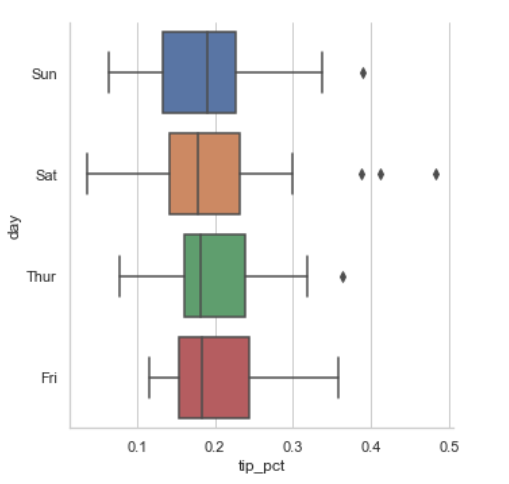
일반적인 용도의 seaborn.FacetGrid 클래스를 이용해서 나만의 패싯 그리드를 만들고 원하는 그래프를 그릴 수 있다.
2010년부터 웹을 위한 대화형 그래픽 도구 개발이 본격적으로 진행되었는데, Bokeh(보케)나 Plotly(플로틀리)같은 도구를 이용하면 웹 브라우저 상에서 파이썬으로 동적 대화형 그래프를 그릴 수 있다.
https://docs.bokeh.org/en/latest/index.html
Bokeh documentation
Bokeh is a Python library for creating interactive visualizations for modern web browsers. It helps you build beautiful graphics, ranging from simple plots to complex dashboards with streaming data...
docs.bokeh.org
Plotly
Plotly's
plotly.com
웹이나 출판을 위한 정적 그래프를 생성한다면 matplotlib과 pandas, seaborn을 기본으로 사용하길 추천한다.