pandas Categorical 데이터
Categorical 데이터
● pandas의 Categorical
● Categorical 연산
● categorical을 이용한 성능 개선
Categorical 메서드
● 모델링을 위한 더미값 생성하기
Categorical 데이터
pandas의 Categorical형을 활용하여 pandas 메모리 사용량을 줄이고 성능을 개선할 수 있는 방법을 소개한다.
하나의 칼럼 내에 특정 값이 반복되어 존재하는 경우는 흔하다. 배열 내에서 유일한 값을 추출하거나 특정 값이 얼마나 많이 존재하는지 확인할 수 있는 unique와 value_counts같은 메서드가 있다.
values = pd.Series(['apple','orange','apple','apple'] * 2)
values
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
dtype: object
pd.unique(values)
array(['apple', 'orange'], dtype=object)
pd.value_counts(values)
apple 6
orange 2
dtype: int64데이터웨어하우스, 분석 컴퓨팅 외 여러 다양한 데이터 시스템은 중복되는 데이터를 얼마나 효율적으로 저장하고 계산할 수 있는가를 중점으로 개발되었다. 데이터웨어하우스의 경우 구별되는 값을 담고 있는 차원 테이블과 그 테이블을 참조하는 정수키를 사용하는 것이 일반적이다.
values = pd.Series([0,1,0,0] * 2)
values
0 0
1 1
2 0
3 0
4 0
5 1
6 0
7 0
dtype: int64
dim = pd.Series(['apple','orange'])
dim
0 apple
1 orange
dtype: objecttake 메서드를 사용하면 Series 내에 저장된 원래 문자열을 구할 수 있다.
dim.take(values)
0 apple
1 orange
0 apple
0 apple
0 apple
1 orange
0 apple
0 apple
dtype: object여기서 정수로 표현된 값은 범주형 또는 사전형 표기법이라고 한다. 별개의 값을 담고 있는 배열은 범주, 사전 또는 단계 데이터라고 부른다. 이런 종류의 데이터를 categorical 또는 범주형 데이터라고 부르겠다. 범주형 데이터를 가리키는 정숫값은 범주 코드 또는 그냥 단순히 코드라고 한다.
범주형 표기법을 사용하면 분석 작업에 있어서 엄청난 성능 향상을 얻을 수 있다. 범주 코드를 변경하지 않은 채로 범주형 데이터를 변형하는 것도 가능하다. 비교적 적은 연산으로 수행할 수 있는 변형의 예는 다음과 같다.
● 범주형 데이터의 이름 변경하기
● 기존 범주형 데이터의 순서를 바꾸지 않고 새로운 범주 추가하기
pandas의 Categorical
pandas에는 정수 기반의 범주형 데이터를 표현(또는 인코딩)할 수 있는 Categorical형이라고 하는 특수한 데이터형이 존재한다.
fruits =['apple','orange','apple','apple'] * 2
N = len(fruits)
df = pd.DataFrame({'fruit': fruits,
'basket_id':np.arange(N),
'count':np.random.randint(3, 15, size=N),
'weight':np.random.uniform(0, 4, size=N)},
columns=['basket_id','fruit','count','weight'])
df['fruit']는 파이썬 문자열 객체의 배열로, 아래 방법으로 쉽게 범주형 데이터로 변경할 수 있다
fruit_cat = df['fruit'].astype('category')
fruit_cat
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
Name: fruit, dtype: category
Categories (2, object): ['apple', 'orange']fruit_cat의 값은 Numpy 배열이 아니라 pandas.Categorical의 인스턴스다.
c = fruit_cat.values
type(c)
pandas.core.arrays.categorical.CategoricalCategorical 객체는 categories와 codes 속성을 가진다.
c.categories
Index(['apple', 'orange'], dtype='object')
c.codes
array([0, 1, 0, 0, 0, 1, 0, 0], dtype=int8)변경 완료된 값을 대입함으로써 DataFrame의 컬럼을 범주형으로 변경할 수 있다.
df['fruit'] = df['fruit'].astype('category')
df.fruit
0 apple
1 orange
2 apple
3 apple
4 apple
5 orange
6 apple
7 apple
Name: fruit, dtype: category
Categories (2, object): ['apple', 'orange']파이썬 열거형에서 pandas.Categorical 형을 직접 생성하는 것도 가능하다.
my_categories = pd.Categorical(['foo','bar','baz','foo','bar'])
my_categories
['foo', 'bar', 'baz', 'foo', 'bar']
Categories (3, object): ['bar', 'baz', 'foo']기존에 정의된 범주 코드가 있다면 from_codes 함수를 이용해서 범주형 데이터를 생성하는 것도 가능하다.
categories =['foo','bar','baz']
codes =[0,1,2,0,0,1]
my_cats_2 = pd.Categorical.from_codes(codes, categories)
my_cats_2
['foo', 'bar', 'baz', 'foo', 'foo', 'bar']
Categories (3, object): ['foo', 'bar', 'baz']범주형으로 변경하는 경우 명시적으로 지정하지 않는 한 특정 순서를 보장하지 않는다. 따라서 categories 배열은 입력 데이터의 순서에 따라 다른 순서로 나타날 수 있다. from_codes를 사용하거나 다른 범주형 데이터 생성자를 이용하는 경우 순서를 지정할 수 있다.
ordered_cat = pd.Categorical.from_codes(codes, categories, ordered=True)
ordered_cat
['foo', 'bar', 'baz', 'foo', 'foo', 'bar']
Categories (3, object): ['foo' < 'bar' < 'baz']
여기서 [foo < bar < baz]는 foo, bar, baz 순서를 가진다는 의미다. 순서가 없는 범주형 인스턴스는 as_ordered 메서드를 이용해 순서를 가지도록 만들 수 있다.
my_cats_2.as_ordered()
['foo', 'bar', 'baz', 'foo', 'foo', 'bar']
Categories (3, object): ['foo' < 'bar' < 'baz']
여기서는 문자열만 예로 들었지만 범주형 데이터는 꼭 문자열일 필요는 없다. 범주형 배열은 변경이 불가능한 값이라면 어떤 자료형이라도 포함할 수 있다.
Categorical 연산
pandas에서 Categorical은 문자열 배열처럼 인코딩되지 않은 자료형을 사용하는 방식과 거의 유사하게 사용할 수 있다. groupby 같은 일부 pandas 함수는 범주형 데이터에 사용할 때 더나은 성능을 보여준다. ordered 플래그를 활용하는 함수들도 마찬가지다.
임의의 숫자 데이터를 pandas.qcut 함수로 구분해보자. 그렇게 하면 pandas.Categorical 객체를 반환한다.
np.random.seed(12345)
draws = np.random.randn(1000)
draws[:5]
array([-0.20470766, 0.47894334, -0.51943872, -0.5557303 , 1.96578057])이 데이터를 사분위로 나누고 통계를 내보자.
bins = pd.qcut(draws,4)
bins
[(-0.684, -0.0101], (-0.0101, 0.63], (-0.684, -0.0101], (-0.684, -0.0101], (0.63, 3.928], ..., (-0.0101, 0.63], (-0.684, -0.0101], (-2.9499999999999997, -0.684], (-0.0101, 0.63], (0.63, 3.928]]
Length: 1000
Categories (4, interval[float64, right]): [(-2.9499999999999997, -0.684] < (-0.684, -0.0101] < (-0.0101, 0.63] < (0.63, 3.928]]사분위 이름을 실제 데이터로 지정하는 것은 별로 유용하지 않아 보인다. qcut 함수의 labels 인자로 직접 이름을 지정하자.
bins = pd.qcut(draws, 4, labels=['Q1','Q2','Q3','Q4'])
bins
['Q2', 'Q3', 'Q2', 'Q2', 'Q4', ..., 'Q3', 'Q2', 'Q1', 'Q3', 'Q4']
Length: 1000
Categories (4, object): ['Q1' < 'Q2' < 'Q3' < 'Q4']
:10
bins.codes[:10]
array([1, 2, 1, 1, 3, 3, 2, 2, 3, 3], dtype=int8)bins에 이름을 붙이고 나면 데이터의 시작값과 끝값에 대한 정보를 포함하지 않으므로 groupby를 이용해서 요약 통계를 내보자.
bins = pd.Series(bins, name='quartile')
results = (pd.Series(draws).groupby(bins).agg(['count','min','max']).reset_index())
results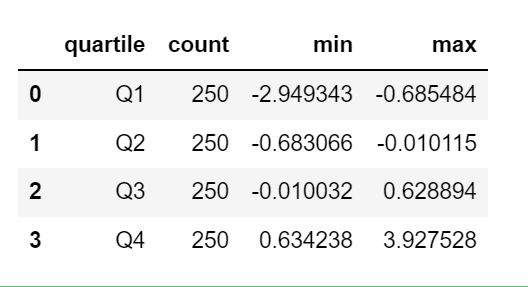
결과에서 quartile 컬럼은 bins의 순서를 포함한 원래 범주 정보를 유지하고 있다.
results['quartile']
0 Q1
1 Q2
2 Q3
3 Q4
Name: quartile, dtype: category
Categories (4, object): ['Q1' < 'Q2' < 'Q3' < 'Q4']categorical을 이용한 성능 개선
특정 데이터셋에 대해 다양한 분석을 하는 경우 범주형 categorical으로 변환하는 것만으로도 전체 성능을 개선할 수 있다. 범주형으로 변환한 DataFrame의 컬럼은 메모리도 훨씬 적게 사용한다. 소수의 독립적인 카테고리로 분류되는 첨만 개의 값을 포함하는 Series를 살펴보자.
N = 10000000
draws = pd.Series(np.random.randn(N))
labels = pd.Series(['foo','bar','baz','qux'] * (N // 4))
categories = labels.astype('category')categories가 labels 에 비해 훨씬 더 적은 메모리를 사용하는 것을 확인할 수 있다.
print(labels.memory_usage())
print(categories.memory_usage())
80000128
10000332범주형으로 변환하는 과정이 그냥 이루어지는 것은 아니지만 이는 한 번만 변환하면 되는 일회성 비용이다.
%time _ = labels.astype('category')
Wall time: 969 ms범주형에 대한 그룹 연산은 문자열 배열을 사용하는 대신 정수 기반의 코드 배열을 사용하는 알고리즘으로 동작하므로 훨신 빠르게 동작한다.
Categorical 메서드
범주형 데이터를 담고 있는 Series는 특화된 문자열 메서드인 Series.str과 유사한 몇 가지 특수 메서드를 제공한다. 이를 통해 categories와 codes에 쉽게 접근할 수 있다. 다음 Series를 살펴보자.
s = pd.Series(['a','b','c','d'] * 2)
cats_s = s.astype('category')
cats_s
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (4, object): ['a', 'b', 'c', 'd']특별한 속성인 cat을 통해 categorical 메서드에 접근할 수 있다.
cats_s.cat.codes
0 0
1 1
2 2
3 3
4 0
5 1
6 2
7 3
dtype: int8cats_s.cat.categories
Index(['a', 'b', 'c', 'd'], dtype='object')이 데이터의 실제 카테고리가 데이터에서 관측되는 4종류를 넘는 것을 이미 알고 있다고 가정하자. 이 경우 set_categories 메서드를 이용해서 변경하는 것이 가능하다.
actual_categories =['a','b','c','d','e']
cat_s2 = cats_s.cat.set_categories(actual_categories)
cat_s2
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (5, object): ['a', 'b', 'c', 'd', 'e']데이터는 변함이 없지만 위에서 변경한 대로 새로운 카테고리가 추가되었다. 예를 들어 value_counts를 호출해보면 변경된 카테고리를 반영하고 있다.
cats_s.value_counts()
a 2
b 2
c 2
d 2
dtype: int64
cat_s2.value_counts()
a 2
b 2
c 2
d 2
e 0
dtype: int64큰 데이터셋을 다룰 경우 categorical을 이용하면 메모리를 아끼고 성능도 개선할 수 있다. 분석 과정에서 큰 DataFrame이나 Series를 한 번 걸러내고 나면 시레로 데이터에는 존재하지 않는 카테고리가 남아 있을 수 있다. 이 경우 remove_unused_categories 메서드를 이용해서 관측되지 않는 카테고리를 제거할 수 있다.
cat_s3 = cats_s[cats_s.isin(['a','b'])]
cat_s3
0 a
1 b
4 a
5 b
dtype: category
Categories (4, object): ['a', 'b', 'c', 'd']
cat_s3.cat.remove_unused_categories()
0 a
1 b
4 a
5 b
dtype: category
Categories (2, object): ['a', 'b']
categorical 메서드
| 메서드 | 설명 |
| add_categories | 기존 카테고리 끝에 새로운 카테고리를 추가한다. |
| as_ordered | 카테고리가 순서를 가지도록 한다. |
| as_unordered | 카테고리가 순서를 가지지 않도록 한다. |
| remove_categories | 카테고리를 제거한다. 해당 카테고리에 속한 값들을 null로 설정한다. |
| remove_unused_categories | 데이터에서 관측되지 않는 카테고리를 삭제한다. |
| rename_categories | 카테고리 이름을 지정한 이름으로 변경한다. 카테고리 수는 변하지 않는다. |
| reorder_categories | rename_categories와 유사하지만 새로운 카테고리가 순서를 가지도록 한다. |
| set_categories | 카테고리를 지정한 새로운 카테고리로 변경한다. 카테고리 추가나 삭제가 가능하다. |
모델링을 위한 더미값 생성하기
통계나 머신러닝 도구를 사용하다 보면 범주형 데이터를 더미값으로 변환(원핫one-hot 인코딩이라고도 함)해야 하는 경우가 생긴다. 이를 위해 각각의 구별되는 카테고리를 컬럼으로 가지는 DataFrame을 생성하는데, 각 컬럼에는 해당 카테고리 여부에 따라 0과 1의 값을 가지게 된다.
cat_s = pd.Series(['a','b','c','d'] * 2, dtype='category')
cat_s
0 a
1 b
2 c
3 d
4 a
5 b
6 c
7 d
dtype: category
Categories (4, object): ['a', 'b', 'c', 'd']
pd.get_dummies(cat_s)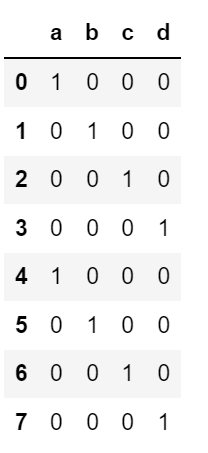
pandas.get_dummies 함수는 이런1차원 범주형 데이터를 더미값을 가지는 DataFrame으로 변환한다.
'Python' 카테고리의 다른 글
| 파이썬 모델링 라이브러리, Patsy (0) | 2022.08.16 |
|---|---|
| 고급 GroupBy 사용 (0) | 2022.08.10 |
| 데이터 집계와 그룹 연산(2) (0) | 2022.07.26 |
| 데이터 집계와 그룹 연산(1) (0) | 2022.07.22 |